A Story of Correctness and Cost with DynamoDB
engineering-softwareThis is a story about a poorly designed system, the costs and pain it brought my company, and how I made it 80% cheaper.
My company builds a platform for students to prepare for medical exams. We offer practice exams, videos, and other study tools. One microservice tracks all student interactions with these features: question answers, playback progress of videos, time spent per question, answer changes from correct to incorrect, any of their markup, completion of various study tasks, and more.
My team had reasons to dislike this service. It was built for an older version of the platform, massive —in terms of connected infrastructure and the lines of (stateful) code— and had few meaningful tests. We didn’t really understand the internals, but it got the job done.
So we were not happy to get reports that occasionally, silently, we were losing student answers.
Problem 1: Correctness
“I answered this question but it shows up as unanswered in my post exam score report.”
We found no trace of the student answering that question and logs showed neither evidence nor error, so we decided this was a mistake. Then a few weeks later, we got another report. And another.
Many attempts at reproduction found that:
- this occurred inconsistently
- actions sent from the FE made it to this service, but were not saved in a table which was supposed to log all actions
- the service did not return an error
- no reports with older frontends
It was time to figure out how this system worked. This seemed interesting so I picked up the ticket.
How it worked: applying an action to activity
I make a lot of Figma diagrams when I’m exploring a system or explaining it to others. I’ll lean on those a lot here.
The old system consisted of a Go codebase interacting with two DynamoDB tables: activity storing gzipped activity blobs, and actions.
Actions are events from the frontend. They modify an activity, a big struct that stores information about a student’s session with an exam, video, quiz, todo, etc.
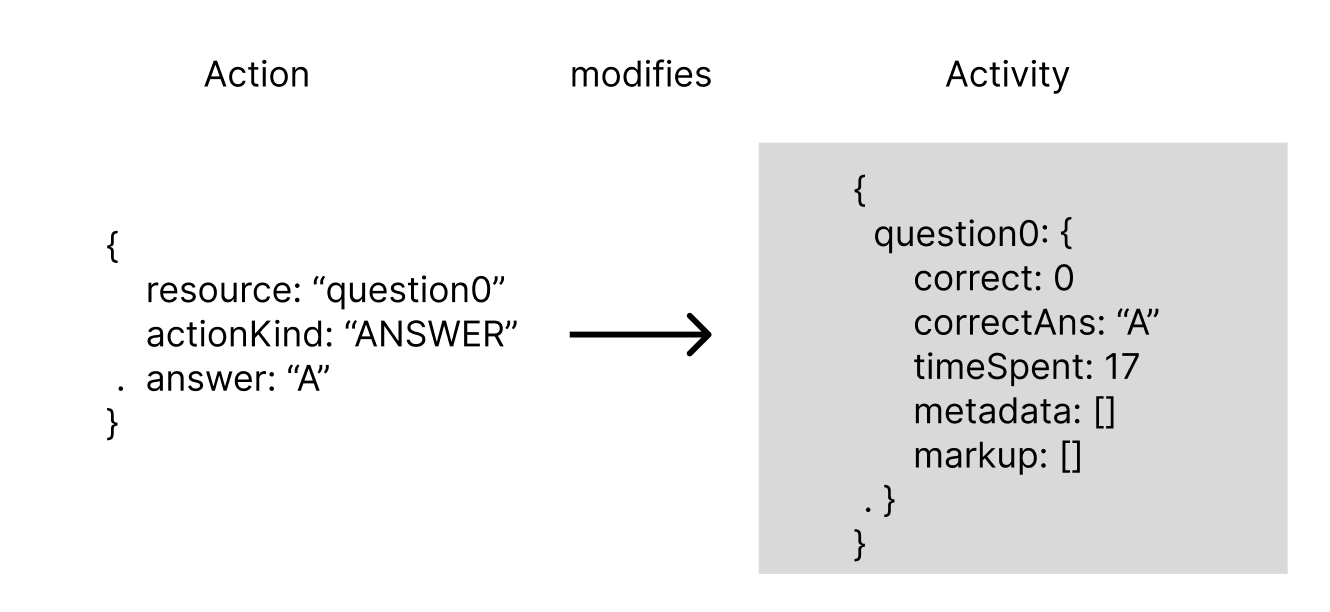
The process began when the microservice received a PUT request with a payload of actions. It read the activity, called a 400+ line stateful function “reduce” to apply those actions to the activity, and overwrote the activity to DynamoDB where it was stored in a single key-value.
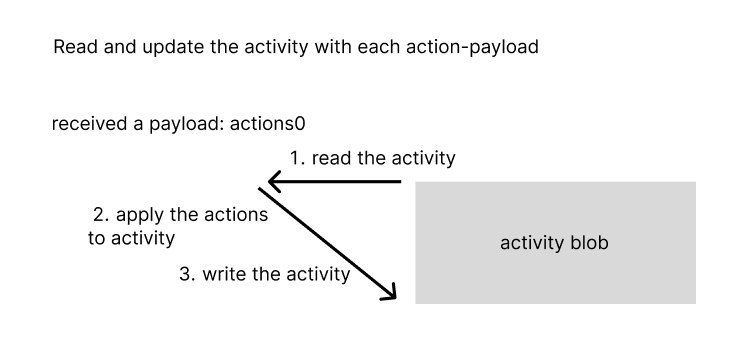
This happened every three seconds so it looked more like this.
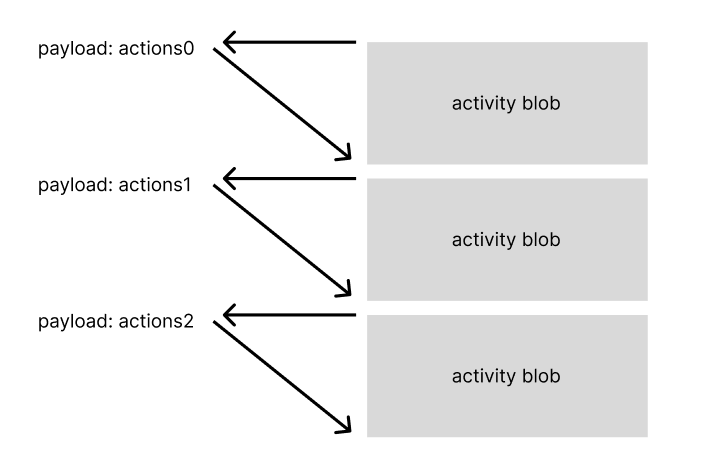
This code ran on AWS Lambda, so we couldn’t know or control which concurrent execution of the codebase processed the payloads.
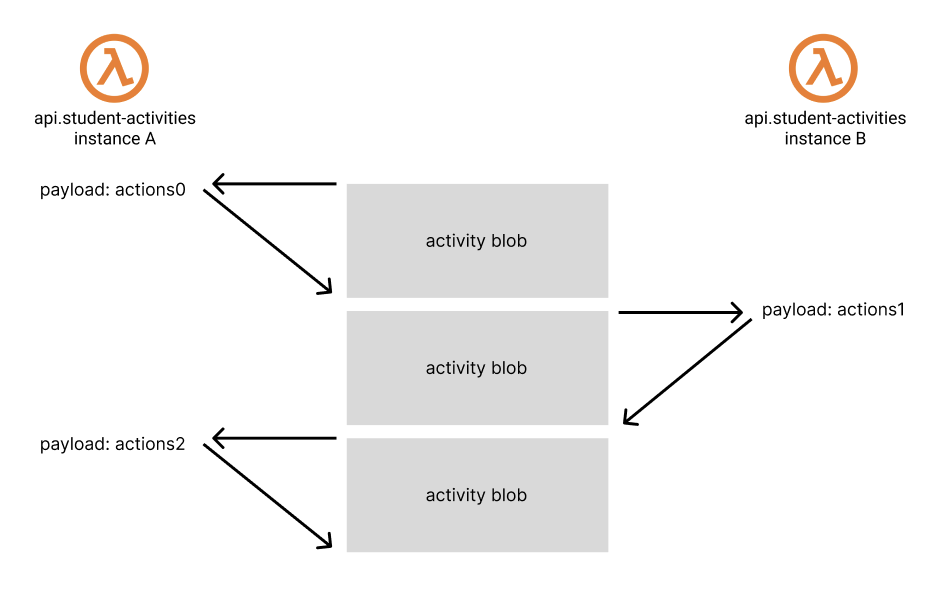
This posed a problem. What if instance A read the activity, but before it finished instance B completed an update to the activity? Instance A would overwrite instance B’s changes and never account for them!
This problem is called the lost update problem. (You should read about it in the industry holy book, Designing Data Intensive Applications)
The old system resolved this problem with a lock. DynamoDB doesn’t really have locks, but it does have transactions, and transactions can be used with conditional expressions to approximate the behavior of a lock. Our system used a field called lastModifiedDate to lock the activity. If instance A went to update the activity blob and the lastModifiedDate in the DB wasn’t the same as when A read the activity it meant another instance had made an update and the transaction should be aborted.
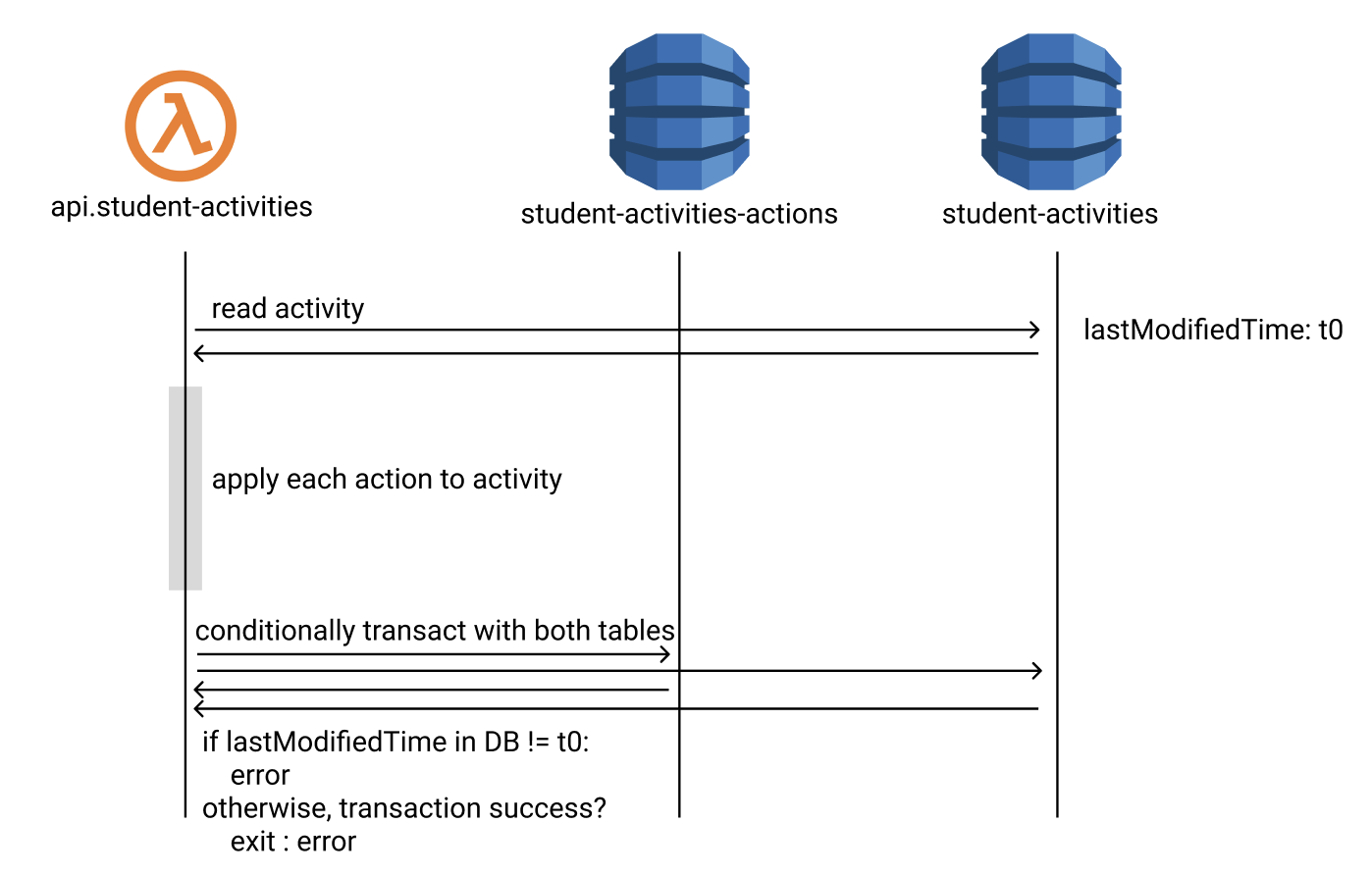
So the transaction failed if the condition wasn’t met: AWS calls this a TransactionCanceledException. Adding more detailed logging revealed other failures such as TransactionConflictException (there’s another ongoing transaction for the primary key), and RequestLimitExceeded (you’ve been throttled, often due to poor table schema design).
The code only accounted for TransactionCanceledExceptions. These triggered a 204 status code which was when we learned that the legacy system’s frontend maintained retried unsuccessful (yes 204 meant retry!) payloads.
Retries did not exist in the new system so I had to deal with the transaction failures, either on the frontend or backend. I talked with the team and we decided on the backend for a few reasons. 1) While building a FE retry solution was on the roadmap (mostly for offline capability) we had a lot of other stuff to do. 2) We wanted to never lose actions sent to the backend. Failures can be fixed later as long as we have a complete, ordered record of a student’s actions.
Implementing a backend solution without dramatically changing the API went well. First, the actions table became like a write-ahead log. Even before reading the activity we’d write actions to the actions table. This process could be idempotent and ordered because the FE assigned each action a unique id and datetime.
Successfully applied actions were now flagged in that table with an appliedDate. Any actions the frontend sent that were already in that table and had an appliedDate could be ignored as duplicates.
Next, the process of reading the activity, applying the actions, and saving the activity was given smarter error handling and a retry loop with exponential backoff. There was some iteration (our tables were really poorly designed when it comes to DynamoDB hot partition concerns) but I won’t go into it except to mention this really great blog post about exponential backoff https://encore.dev/blog/retries.
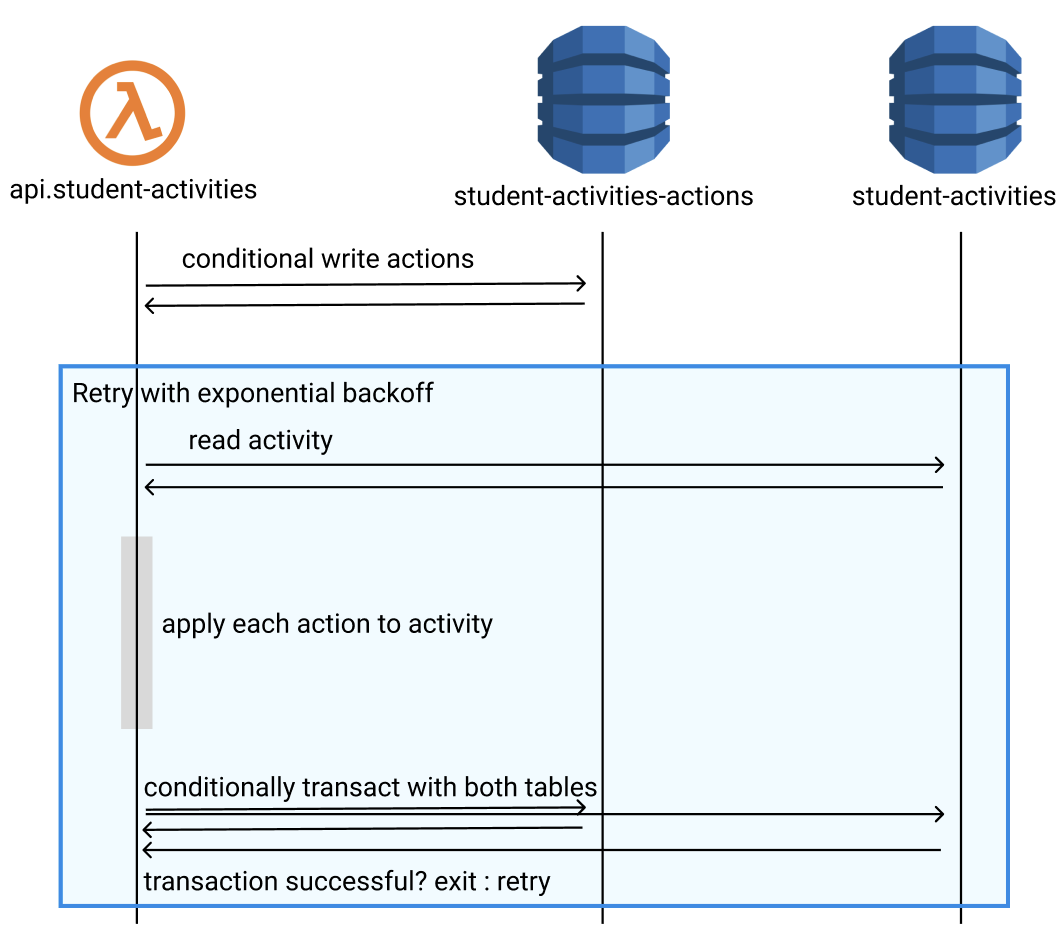
Monitoring showed no more throttling events and significantly fewer transaction conflicts and cancellations —and most importantly none that fail through the retry loop! We haven’t had any student reports since! This was a huge win, and I didn’t have to think about this service for a few months.
Problem 2: Costs
Then there were layoffs. And cost cutting. AWS costs were too high, and we were looking around our platform for ways to dramatically cut costs. This service was a main contributor and seemed designed to throw money at DynamoDB. (This was only one of the problems I discovered from our moving fast, we were basically paying double lambda costs to provision the rarely used green part of our blue-green deployment —but that’s another story)
That brings us to challenge two. Dramatically reduce costs while continuing to use DynamoDB (a preference from on-high), changing the service’s API as little as possible, and maintaining the functionality of its existing asynchronous architecture.
Investigating the costs
DynamoDB costs depend on how and how much data is read or written. Strongly consistent reads cost more than eventually consistent, transactions cost more than normal operations, writing or reading more data costs more than less data. This system maxed all three.
Every three seconds our frontend sent at least one action to the backend. That payload triggered an eventually consistent read to get key information required to do a second strongly consistent read of the activity key-value in DynamoDB (lovely). Next —as in the previous section— a transaction marked the action key-values as applied and overwrote the activity. So we’d read and write the entire activity blob every few seconds —even if only a small part was modified.
What could we change to achieve the same correctness guarantees with less cost?
Low hanging fruit
Our frontend sends heartbeat actions to the backend to say “I’m alive, a student is working on this question” and to help us track time spent per question. Investigation revealed that heartbeats made up >90% of actions sent. We added offline action storage and a queued retry system on the frontend so there was no longer a strong need to send a heartbeat action every three seconds. Fifteen seconds maintained the correctness of the time tracking code and reduced costs a bit.
Big Fix Idea 1: Fragments
Storing the entire activity in one-key value introduced the main two cost drivers; requiring transactions to prevent the lost update problem and needing to read and write the whole activity even for small updates. So what if we split the big object of maps that is activity into many separate key values?
Let me briefly introduce the several structs and maps contained in activity:
- activityAggregate: a struct representing top level, overall performance (total time spent, total questions correct/incorrect, a map of questionId to markup objects, etc.)
- sectionAggregate: a section is series of questions, this tracked the same aggregate struct as above for each section
- questionGroup: a map from each group of questions to the same aggregate struct
- questionAggregate: same as above but for individual questions
- questionAnswer: map from question uuid to information about the questions correct answer and metadata, filled on activity creation
We could turn these into separate key-values in DynamoDB. Time to build a prototype! It took a few passes to come up with a single-table schema supporting all the old access patterns —outlining a new table and thinking through the access pattern until discovering a dead-end caused by the limited nature of the DynamoDB API— but eventually one showed promise!
For reads we’d query all the key-values —pretty much the same cost as reading the one big key-value— and for writes we could only read and write to the fragments (read: key-values) impacted by the actions.
A single answer action only impacts the current questionAggregate, current questionGroup, sectionAggregate, and top level activityAggregate. This would easily work with this approach.
However, separate answer actions being written at the same time from different lambdas could recreate our earlier problem because there would be overlapping updates to sectionAggregate and activityAggregate possibly leading to the lost update problem.

But there is a way to prevent this without transactions, locks, and retries
Commutative operations: when the order of operations doesn’t affect the final result.
A simple example: to update the YouTube like counter non-commutatively you could read the current value, compute current_value + 1, and write the new value. If that happens from multiple instances you could get the lost update problem.
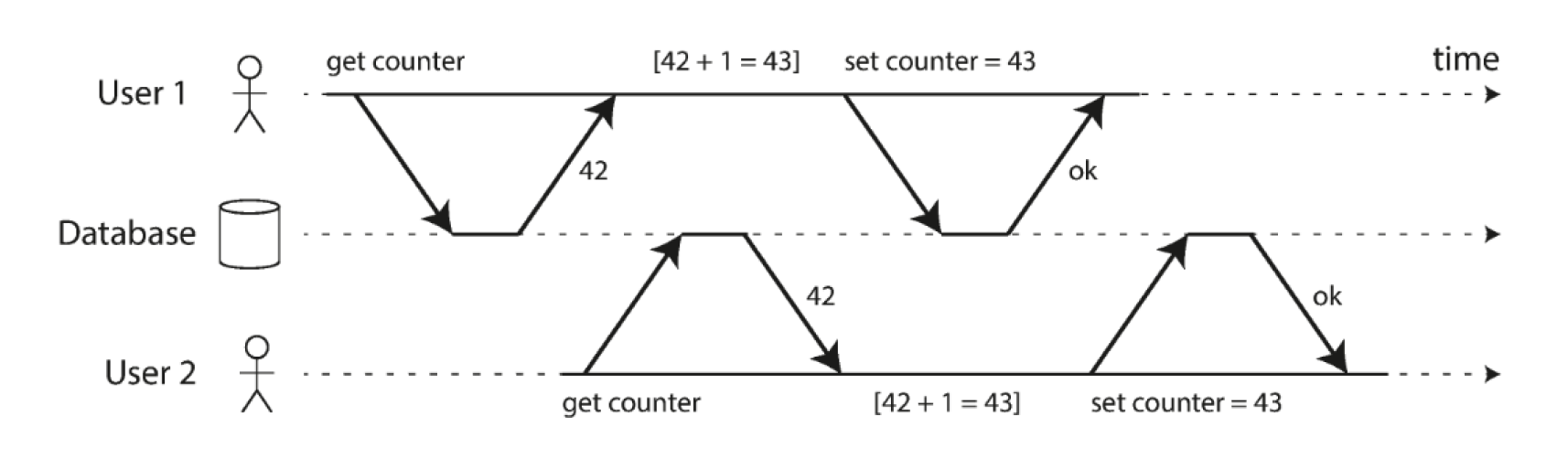
To do this commutatively we could use a database increment operation. In DynamoDB that would be an update operation like SET counter = counter + 1. That way counter gets +(1 * n) regardless of how many n increments come through simultaneously.
This is a bit harder for fields that need bounding: the number of correct or incorrect questions in a section should not be less than zero or greater than the number of questions in the section:

We can solve this using set operations that eliminate the need for reads and conditional expressions:

Commutative operations are great for our goal to reduce costs because we can forgo expensive transactions and often just write without having to do a read!
Roadblocks solved, I continued with the prototype, implementing a subset of the many action kinds available. The 400 line function that applied actions to an activity was replaced with a pure function that took in an action and spit out struct containing a set of commutative operations to send to DynamoDB. This was a win because it was developed with unit tests —which the massive, old, stateful function didn’t have! For the sake of speedy prototyping, I also left some of the aggregations generated on read requests instead of computed commutatively.
Once the prototype reached the point where it could support enough actions to take an exam I began to measure cost impact. Per action payload we would use 20-70 “aws units” instead of ~200. That meant it was time to talk about the prototype to other teams.
This system supported features in 4 new frontend platforms, provided data synchronously to 2 frontends, and triggered extensive asynchronous processes (see diagram). Several teams would need to accept this fragment idea.
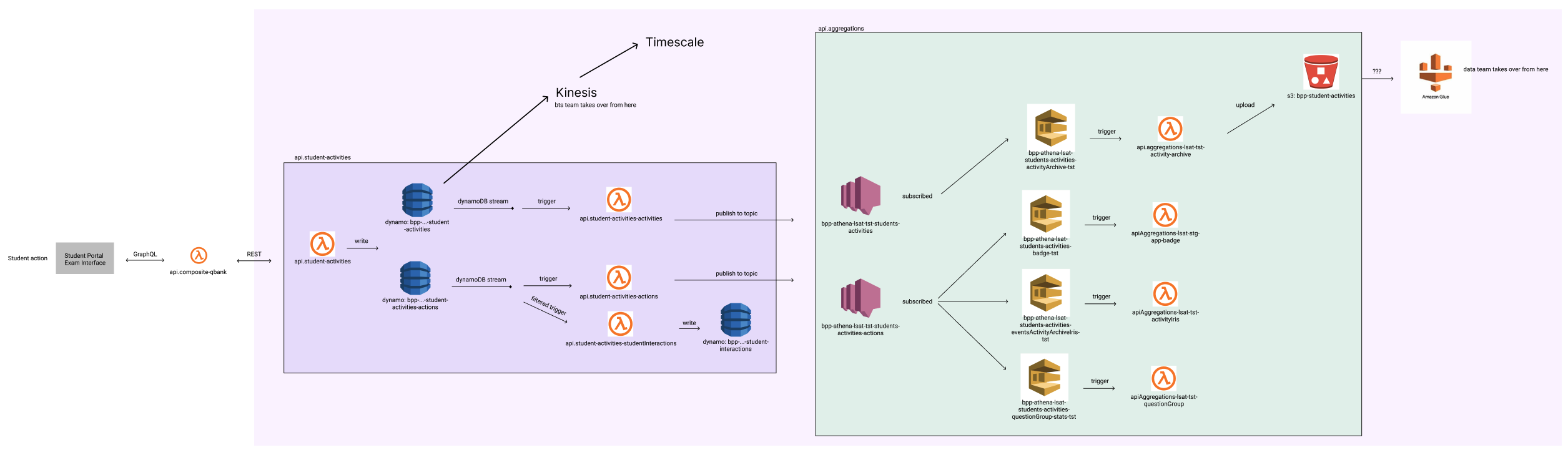
The biggest impacts of this change were:
- the regular sending of a payload of actions wouldn’t return the next activity state —less reading of the activity is kinda the whole goal.
- some of the events triggering async architecture would have different payloads or require additional external calls.
- one of the async processes triggered by actions payloads depended on activity state and would require one frontend to send a bit more info in the action payload.
I met with engineering teams, explaining the cost drivers, proposed solution, and impact. Meanwhile I hacked on idea 2.
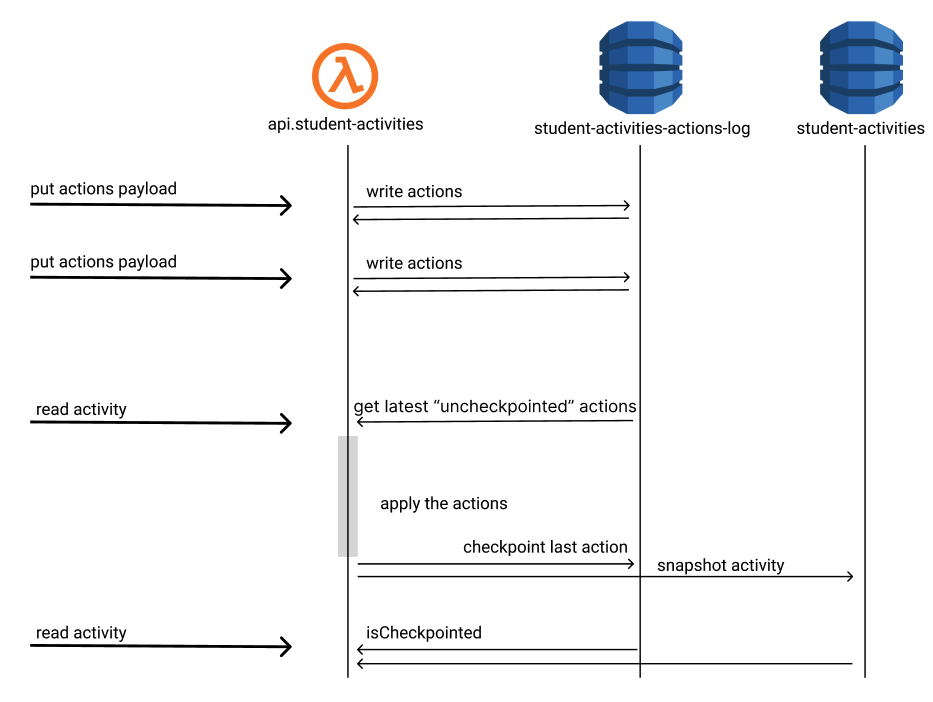
Idea 2: Log and Snapshot
Idea 2 hit me after building some aggregations on read requests in the fragment system. What if action payloads were saved to a log and we delayed building the whole activity until a read? We write way more often than we read, so this would be cheaper. Our exam frontend didn’t need the next activity state —it already maintained state for optimistic updates. Could this be fast enough to work for the 99th percentile of actions sent before the next read?
A prototype building an activity from several thousand actions was fast enough. A second prototype wrote the actions to the log, returned 200, then built an activity on read. A third saved a “snapshot” of the new activity in a new DynamoDB table, so subsequent reads wouldn’t need to rebuild the activity.
Idea 2 would be easier to deliver than Idea 1 since it reused existing, production-tested code to apply actions to an activity. It also required fewer changes to asynchronous processes. But it was not without downsides. The main risks seemed like
- This could impact site performance.
- Failures would occur on-read instead of on-write. What might that mean for our ability to recover from errors?
- Some feature or process depending on this system would not be able to deal with moving to an approach where sending actions did not return the next activity state.
I met with my old manager —who architected and wrote most of the original platform— and we agreed that
- Prototypes showed #1 wasn’t a concern, and performance could be addressed other ways if problems arose.
- Unrecoverable failures almost never occurred in the code we’d be reusing (and logs verify this), so we’d have to be careful but this wasn’t unreasonably risky.
- We couldn’t identify incompatible features, but if we did, we could leave them on the old system.
DynamoDB’s persnicketiness meant that the actions table (the write-ahead log of actions) needed to be replaced because we needed consistent reads of the latest actions for an activity and the index doing that was in a global secondary index which does not support consistent reads. So a new table actions-log was born and made usable with the old and new systems so that all new actions would be written to this table regardless if the snapshot system’s feature flag was on or off. I had planned to use a new activities table as well, but reads needing to look in both tables and the difficulty of rolling back changes led to later prototypes switching back to use of the original table.
I got this working in a local environment, then a test environment, and found myself at the point where we needed to decide between the two systems.
Choosing between the Fragment and Snapshot Systems:
Fragment:
- cooler
- separate key-values might mean easier support of some later roadmap features
- high complexity of bringing to production and more time needed to solve those problems
- significant changes to asynchronous system
- harder to teach
- future attributes of activity might not be commutatively updatable, increasing costs a bit
Snapshot:
- not sexy
- likely cheaper based on usage patterns
- kinda clunky to build this on read, possible performance concerns, at least increases coupling of frontend and backend components
- easier to deploy and rollback, maybe less risk since we lean on old code just run at a different time
- easier to teach devs the system (less math and DynamoDB knowledge required)
- shorter delivery time
I think it came down to delivery time. Snapshot it was.
Deployment
My goal was to get this up into the highest pre-production environment, so other devs and internal users could unknowingly be switched to this system and help test it. That was built quickly for the core synchronous functionality, with support for the asynchronous processes and assorted minor quirks of 5 years of features coming two weeks later.
This revealed two issues with one team’s use of the service that we worked together to fix. Then it was time for production, immediately rolling out the frontend updates, the code to use the new actions-log table, and the support for asynchronous changes setting us up to slowly activate the feature flags for the snapshot system. There’s a lot more detail in the deployments but this post is long enough!
Results
DynamoDB costs for 16 environments (tst, staging, beta, prod * 4 business lines) are shown in red going down day-by-day as these changes make their way to prod.
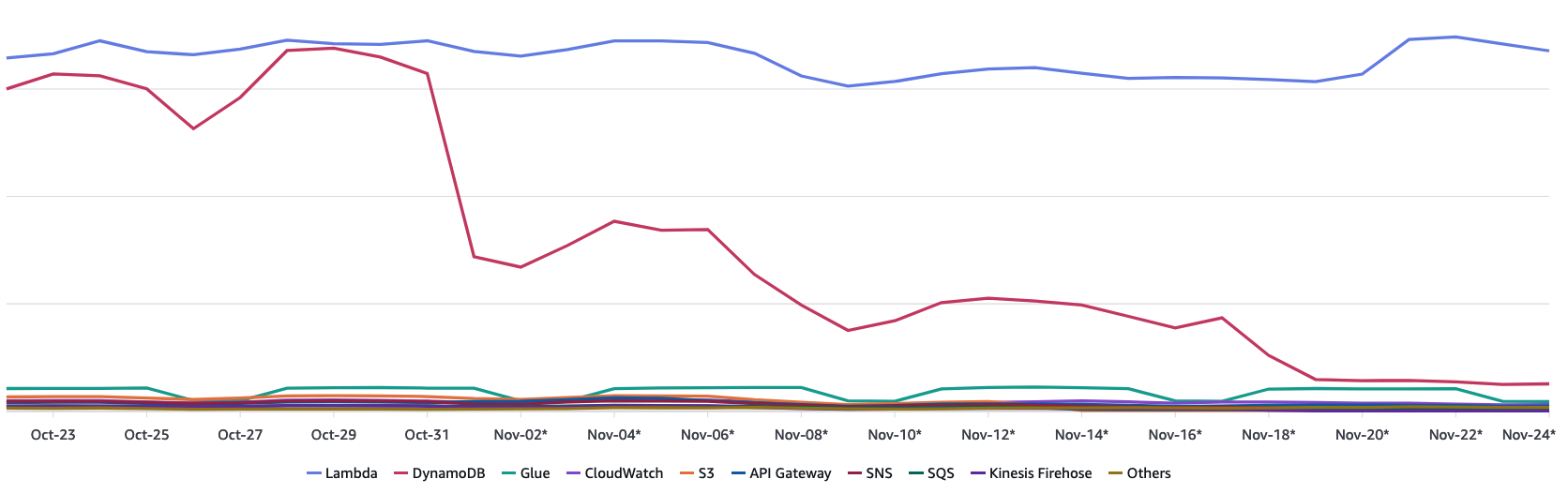
DynamoDB costs across all non-legacy environments were reduced by about 84%. I earned my salary this year.
These cost reductions are a function of using fewer transactions, but mostly just reading and writing less often.
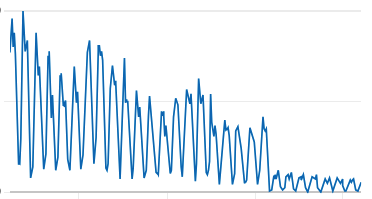
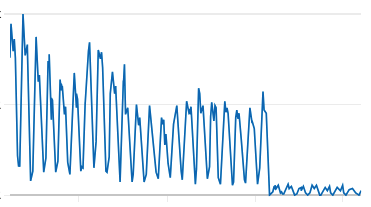
activities DynamoDB table after the snapshots feature flag is activated.
Takeaways
No one owned this service. No team had the responsibility, awareness, or time to recognize the problems and inefficiency here. With no one to object to non-cohesive extensions to the activities struct and ad hoc additions to the asynchronous processes this became a mess. Millions of dollars of AWS costs could have been saved had this been addressed earlier. And on the dev side we’re still dealing with the implications of design choices like using gzipped blobs in a single key-value and the complexity of the asynchronous system —possibly things to address in future work.
My next thought is that DynamoDB is great. I really like it. But it is a very specific tool. My company’s choice to default to DynamoDB often means application-side complexity and increased costs. The limited access patterns don’t play great with moving fast and workarounds usually involve additional roundtrips, many indices, expensive calls, or throwing away a prototype to redo the table schema. It’s great to not need a database admin, worry about connection limits, or availability/durability/etc., but my company must do a better job teaching DynamoDB’s access patterns, best practices, and costs.
We are taking steps in that direction. I lead a fortnightly (down with bi-weekly ambiguity) meeting where we discuss a blog post, talk, or technical work. I would not have been able to do this project without having read papers and books like Designing Data Intensive Applications.
Another random takeaway is how useful Figma is as a diagramming tool. I can quickly show, duplicate, and modify diagrams which is so useful when communicating remotely and trying to solve hairy problems.
Finally, I love this kind of work. I’m looking forward to learning from the next database/distributed-system problem.